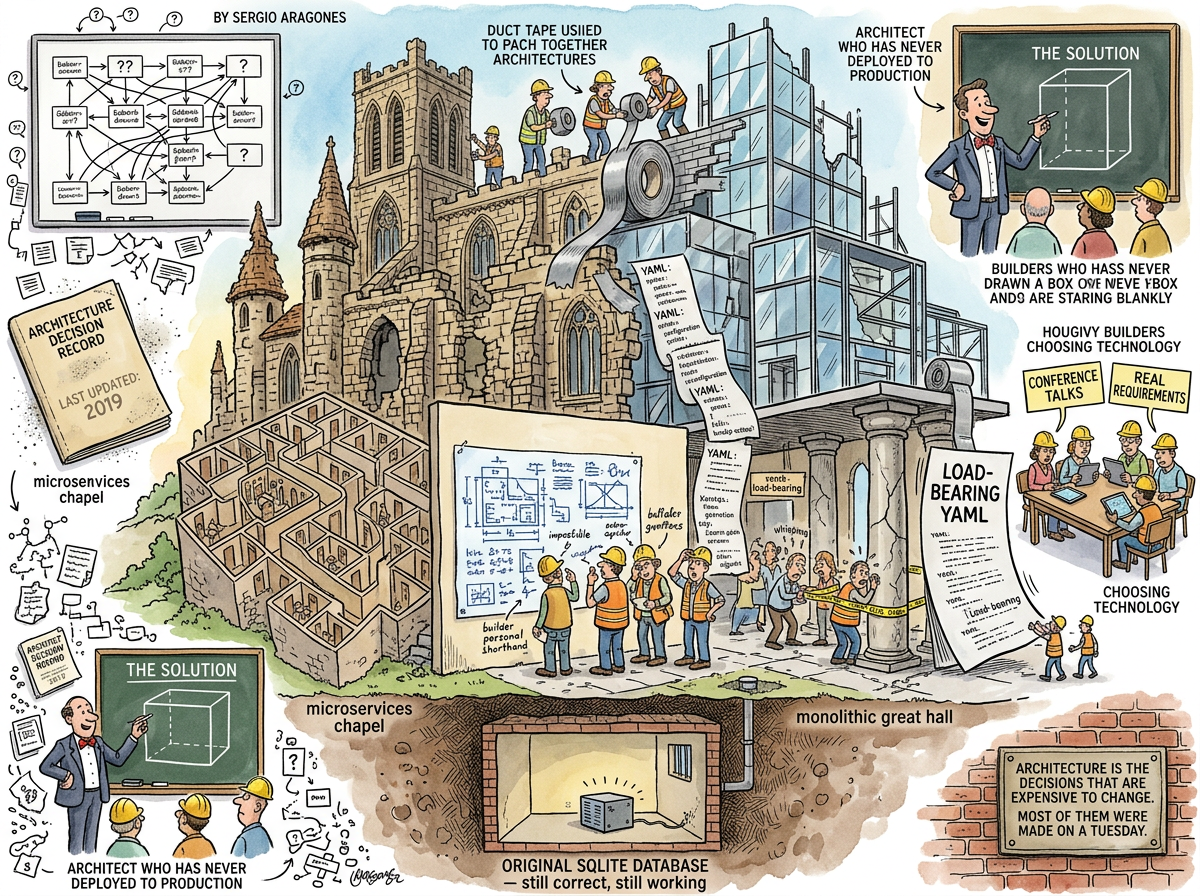
Software Architecture is the set of decisions about a system that are expensive to change later — made early, made under uncertainty, made by people who will have left the company by the time the consequences arrive, and documented in a Confluence page that was last updated eighteen months ago and contains a diagram with fourteen boxes, eleven arrows, and zero explanations of why any of it is the way it is.
Architecture is not the code. Architecture is the shape of the code — the decisions that constrain every subsequent decision: which language, which database, which communication patterns, how many services, where the boundaries are. Get these right and the code writes itself. Get these wrong and no amount of clean code, test coverage, or sprint velocity will save you.
“Your monolith worked. Your forty-seven microservices don’t. That’s not theory. That’s your Grafana dashboard.”
— The Consultant, Interlude — The Blazer Years
The Fundamental Problem
The fundamental problem of software architecture is that the decisions that matter most must be made when you know the least.
At the beginning of a project, you know almost nothing: how many users you’ll have, what they’ll actually do, which features will matter, where the bottleneck will be, what the business will look like in two years. This is the moment when you must decide: monolith or microservices? SQL or NoSQL? Synchronous or event-driven? One repo or many? These decisions will be load-bearing. They will be expensive to change. And they are being made on a Tuesday morning by someone who has a conference talk to catch at 2 PM.
The decisions that can be easily changed later — variable names, function signatures, UI layout — are not architecture. Architecture is specifically the decisions that cannot be easily changed. This is why architecture matters, why it’s difficult, and why most organizations get it wrong: they spend weeks debating variable names (cheap to change) and hours choosing the database (expensive to change).
The Architect Problem
Software architecture has an architect problem: the people who make the decisions and the people who live with the consequences are often different people.
The Ivory Tower Architect draws boxes on whiteboards, writes Architecture Decision Records, chooses technology stacks based on ThoughtWorks Radar, and has not deployed code to production since the Obama administration. The Ivory Tower Architect’s decisions are elegant, internally consistent, and wrong — wrong because they were made without the feedback loop of production, without the muscle memory of debugging at 3 AM, without the knowledge that comes from living inside the system rather than drawing pictures of it.
The Accidental Architect is the senior developer who made a decision in Sprint 3 because someone had to, and now the entire system is shaped by that decision. Nobody called it architecture at the time. Nobody wrote a decision record. But the database choice, the API style, the deployment model — these were set in Sprint 3 and they are now load-bearing walls that three teams build against.
The best architecture comes from neither. The best architecture comes from developers who build and think, who write code and consider consequences, who make decisions deliberately while remaining close enough to production to know which decisions to reverse. The Agile Manifesto’s phrasing: “The best architectures, requirements, and designs emerge from self-organizing teams.” This is correct and universally ignored by organizations that hire architects to tell self-organizing teams what to do.
The Conference-Driven Architecture
A significant percentage of architectural decisions are made not by analyzing requirements but by attending conferences.
The pattern:
- CTO attends conference
- Speaker from Netflix/Google/Spotify describes their architecture
- CTO returns to a company with 1,200 users and 12 developers
- CTO mandates the architecture designed for 200 million users and 1,600 engineers
- The Grafana dashboard turns into a Christmas tree
This is The Spotify Model applied to infrastructure. It is also Conway’s Law in reverse: instead of the architecture reflecting the organization, the organization is restructured to reflect an architecture borrowed from a company with entirely different constraints.
Netflix has microservices because Netflix has 200 million users, 10,000 engineers, and deployment requirements that demand independent service scaling. Your company has microservices because your CTO went to QCon.
“You designed a complex system from scratch. Gall’s Law says it won’t work. It doesn’t work. The law is not theoretical.”
— The Consultant, Interlude — The Blazer Years
The Monolith Was Fine
The most controversial sentence in modern software architecture: the monolith was fine.
The monolith responded in 47 milliseconds. The microservices respond in 2.3 seconds. The monolith cost £400 a month. The microservices cost £47,000. The monolith ran at 3% CPU. The microservices produce a Grafana dashboard that requires a full-time SRE to interpret.
The monolith was not replaced because it was slow, expensive, or unreliable. The monolith was replaced because it was unfashionable. The conference said microservices. The blog posts said microservices. The job postings said microservices. The monolith said “I’m running at 3% CPU” but nobody was listening because the monolith doesn’t have a conference talk.
This is not an argument against microservices. Microservices solve real problems at real scale. This is an argument against adopting an architecture designed to solve problems you don’t have, in an organization that doesn’t resemble the organization that designed it, because someone attended a conference.
See: The Monolith, Microservices, Gall’s Law.
The Architecture Tax
Every architectural decision carries a tax — an ongoing cost paid in complexity, coordination, and cognitive load:
| Architecture | Tax |
|---|---|
| Monolith | All changes in one codebase (which is fine until it isn’t) |
| Microservices | Network latency, distributed transactions, operational complexity, 47 Grafana dashboards |
| Event-driven | Eventual consistency, debugging distributed state, “have you checked the dead letter queue?” |
| Serverless | Cold starts, vendor lock-in, debugging by reading CloudWatch logs |
| Service mesh | Now you have two networks to debug |
The correct architecture minimizes the total tax for your system, your team, your constraints. Not Netflix’s constraints. Not Spotify’s constraints. Yours.
The Lizard’s architecture — one binary, one database, one repo — pays the monolith tax: all changes in one codebase. This is fine because there is one developer. The tax for one developer in a monolith is zero. The tax for one developer in a microservices architecture is approximately infinite, because the developer must now operate a distributed system alone, which is like asking one person to play both sides of a chess game while also being the board.
The Load-Bearing YAML File
In every sufficiently complex system, there exists a YAML file (or JSON file, or Terraform file, or Kubernetes manifest) that nobody fully understands, that was written by someone who left two years ago, and that controls something critical — routing, deployment, secrets management, or the configuration of the configuration system.
This file is the actual architecture. Not the boxes on the whiteboard. Not the decision records in Confluence. The YAML file. It is load-bearing. It is undocumented. It is the truth.
Measured Characteristics
Decisions made with full information: 0%
Decisions made on a Tuesday: disproportionately many
Architecture diagrams that match production: ~20%
Architecture Decision Records up to date: ~10%
Monolith response time: 47ms
Microservices response time (same workload): 2.3s
Conference talks about monoliths: few
Conference talks about microservices: thousands
Systems that need microservices: fewer than have them
Systems that regret microservices: more than admit it
Architects who deploy to production: rare
Developers who think about architecture: the good ones
YAML files nobody fully understands: at least 1 per system
The Lizard's services: 1
The Lizard's databases: 1
The Lizard's Grafana dashboards: 0