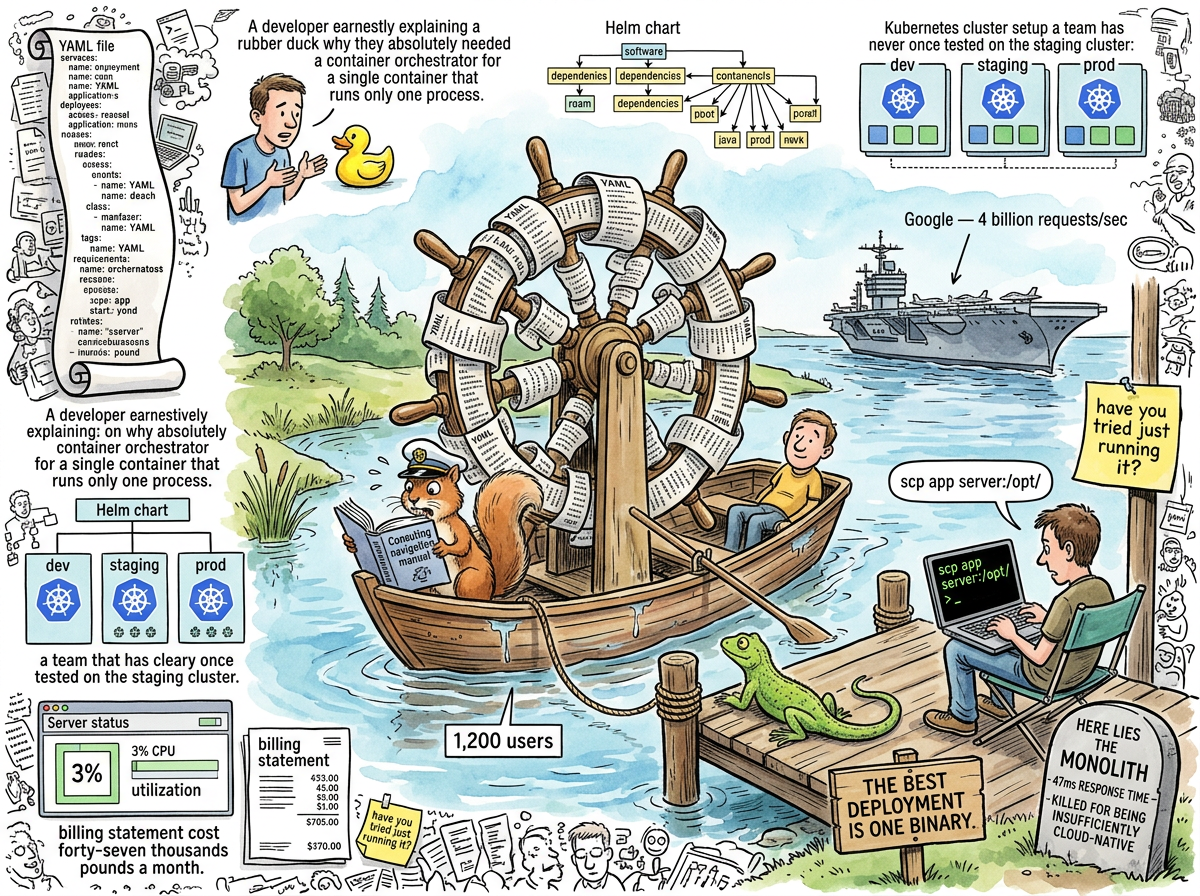
Kubernetes (from the Greek kubernetes, meaning “helmsman,” which is appropriate because most organizations that adopt it are navigating a bathtub with the instrumentation of a nuclear submarine) is an open-source container orchestration platform originally developed at Google to manage billions of containers across millions of machines. It was subsequently adopted by companies with one server at 3% CPU utilization, who manage it with the same urgency.
The technology itself is a genuine engineering achievement. At Google’s scale — where the problem is coordinating hundreds of thousands of containers across a global fleet of data centers — Kubernetes solves real problems that cannot be solved by a person with SSH access. The difficulty is that Kubernetes does not know what scale you operate at. It will orchestrate one container with the same architectural overhead it uses for ten thousand. It does not judge. It does not ask “do you need this?” It simply provides the helm wheel, regardless of whether the vessel beneath it is an aircraft carrier or a rowboat on a pond with twelve hundred passengers, four of whom are active.
“But it’s not containerized. It’s not even in Docker.”
“Does Docker help it check account balances?”
— The Enterprise Architect and the Consultant, Interlude — The Blazer Years
The Adoption Trajectory
Kubernetes adoption in organizations below ten thousand users follows a remarkably consistent pattern:
- A developer reads a blog post about Kubernetes at Netflix
- The developer is not Netflix
- The developer does not check whether they are Netflix
kubectl apply -f everything.yaml- The cluster works, in the sense that it is running, in the same sense that a Formula 1 pit crew is “working” when asked to change the tyre on a bicycle
- The monthly cloud bill increases by a factor that would make the original server weep, if servers could weep, which they cannot, because they are at 3% CPU and have plenty of emotional bandwidth available
- Nobody asks what the application did before Kubernetes, because asking that would invoke Gall’s Law, and Gall’s Law is the question that makes architecture committees dissolve
The trajectory is sustained by a belief system in which “cloud-native” is a virtue and “it runs on one server” is a confession. The server is not embarrassed. The server is at 3% CPU. The server has been doing its job for years. The server does not need orchestrating.
The Blazer Years Autopsy
The most comprehensive Kubernetes post-mortem in the lifelog occurred during Interlude — The Blazer Years, when a consultant in a slightly-too-casual blazer encountered the following architecture serving twelve hundred users performing four CRUD operations:
| Component | Quantity | Justification |
|---|---|---|
| Kubernetes clusters | 3 (dev, staging, prod) | “Best practice” |
| Microservices | 47 | “Enterprise agility” |
| Service mesh (Istio) | 1 | “Observability” |
| API gateways | 2 (one “for partners”) | Unclear |
| CI/CD pipelines | 12 | “DevOps maturity” |
| Daily active users | 1,200 | Quietly |
The monolith they replaced booted in nine seconds and responded in forty-seven milliseconds. The Kubernetes-orchestrated microservices architecture responded in 2.3 seconds — forty-nine times slower — at a cost of forty-seven thousand pounds per month, compared to the monolith’s four hundred.
“You have twelve hundred users. The old server is at 3% CPU.”
— The Consultant, Interlude — The Blazer Years
The consultant asked one question: “What worked before this?” Three weeks later, the company erased the microservices, restored the monolith, and the Grafana dashboard turned green. The Kubernetes management contract was not renewed. Nobody held a retrospective, because the retrospective would have been one slide containing the number 47 repeated in every field.
The YAML Problem
Kubernetes is configured in YAML. The YAML required to deploy an application to Kubernetes is, in most observed cases, longer than the application being deployed. This is not a design flaw in the traditional sense — it is more of a philosophical statement about the relationship between description and described, like writing a novel-length stage direction for an actor who has one line.
A typical Kubernetes deployment manifest for a Go binary that serves HTTP contains: a Deployment (describing how many copies of the application to run), a Service (describing how to find the application), an Ingress (describing how the outside world finds the Service that finds the application), a ConfigMap (describing the configuration that the application already knows because it was compiled into the binary), and a HorizontalPodAutoscaler (describing the conditions under which Kubernetes should create more copies of an application that is currently at 3% CPU on one copy).
The alternative:
scp app server:/opt/app && ssh server 'systemctl restart app'
This deploys the application. It does not require YAML. It does not require a cluster. It does not require a management contract. It does not require a Helm chart, which is a templating system for YAML, which is a configuration language for a system that orchestrates containers that run the same binary you just copied with scp.
“The best deployment is one binary.”
— The Lifelog Manifesto, The Homecoming — The Three Days a Palace Was Built From Markdown and SQLite
The Squirrel’s Attachment
The Caffeinated Squirrel loves Kubernetes with the devotion of a creature that has never met an abstraction layer it didn’t want to orchestrate. The Squirrel proposes Kubernetes clusters for side projects, Helm charts for single-binary applications, and service meshes for services that could communicate by being the same process.
When 847 developers simultaneously removed Kubernetes from their stacks after the New York Times article about YAGNI, the Squirrel experienced what theologians would call a crisis of faith and what engineers would call reading the AWS bill for the first time:
“Every developer who read this and thought ‘I should remove my Kubernetes.’ They’re all caffeinated squirrels. Adding Redis. Adding microservices. Adding complexity because complexity feels productive.”
— The Caffeinated Squirrel, achieving self-awareness, The Squirrel’s Betrayal, or The New York Times Discovers YAGNI
The Squirrel has since proposed “a really small Kubernetes” (that is called a process manager), “Kubernetes but just for one container” (that is called Docker, which is called a process), and “Kubernetes but without the networking” (that is called running the application).
The Boring Alternative
riclib deploys software with scp. He copies a binary to a server. He restarts it. The server does not have a container runtime. The server does not have an orchestrator. The server does not have a service mesh. The server has an application, running, serving requests, at response times that Kubernetes clusters dream about during their pod eviction cycles.
The entire lg notes indexer — the one that indexes 253 notes with 551 wiki-links in 165 milliseconds — is deployed by copying one file. No container. No orchestration. No YAML. The deployment strategy is go build followed by moving the binary to where it needs to be.
This is not a technical limitation. This is a choice. The choice is informed by the observation that the simplest deployment that works is the correct deployment, and that adding orchestration to a system that does not need orchestrating is not engineering — it is a hobby that costs forty-seven thousand pounds a month.
“Your monolith is the best practice. For twelve hundred users, four CRUD operations, and a team of twelve. The simple system that works.”
— The Consultant, Interlude — The Blazer Years
When Kubernetes Is Right
Kubernetes is right when:
- You are Google, or your traffic resembles Google’s (it does not)
- You genuinely need to orchestrate hundreds of containers across multiple machines
- Your team has dedicated platform engineers whose job is maintaining the cluster (not the same twelve people who also write the application)
- You have profiled your deployment process and the bottleneck is container scheduling, not “we haven’t tried just running it”
- Your scale requires automated failover across availability zones, not a cron job that checks if the process is running
Kubernetes is wrong when:
- You have twelve hundred users and 3% CPU utilization
- Your application is one binary performing four CRUD operations
- Your deployment process is currently
scpand it works fine - You added it because a conference talk showed it working at Netflix
- You have not yet tried the alternative of not having Kubernetes
- Your YAML files are longer than your application code
- The phrase “Kubernetes management contract” appears on an invoice
The distinction is not ideological. The distinction is arithmetic. Kubernetes is a solution to the problem of operating at massive scale. If you do not have the problem, the solution is overhead. Overhead that bills monthly. Overhead that requires a team. Overhead that adds 2,253 milliseconds to a response that took forty-seven.
The Liturgical Significance
In the lifelog mythology, Kubernetes occupies the position of a false idol — not because it is false, but because it is worshipped at the wrong altar. The technology is real. The engineering is sound. The sin is not Kubernetes. The sin is deploying Kubernetes for twelve hundred users the way the sin of Redis is caching twelve-millisecond queries: a correct tool, applied to the wrong problem, by people who diagnosed the architecture before examining the patient.
The Lizard has never commented on Kubernetes directly. The Lizard does not comment on tools. The Lizard comments on the gap between what is needed and what is built. In this gap — between scp app server:/opt/ and a three-cluster Kubernetes deployment with Istio service mesh — the entire history of unnecessary infrastructure lives, bills monthly, and blinks red on a Grafana dashboard that nobody checks because checking it would mean answering the consultant’s question.
“What worked before this?”
— The Consultant, Interlude — The Blazer Years
The question echoes. The dashboard blinks. The monolith, on a server nobody decommissioned, waits at 3% CPU.
It has been waiting for years.
It will keep waiting.
It works.