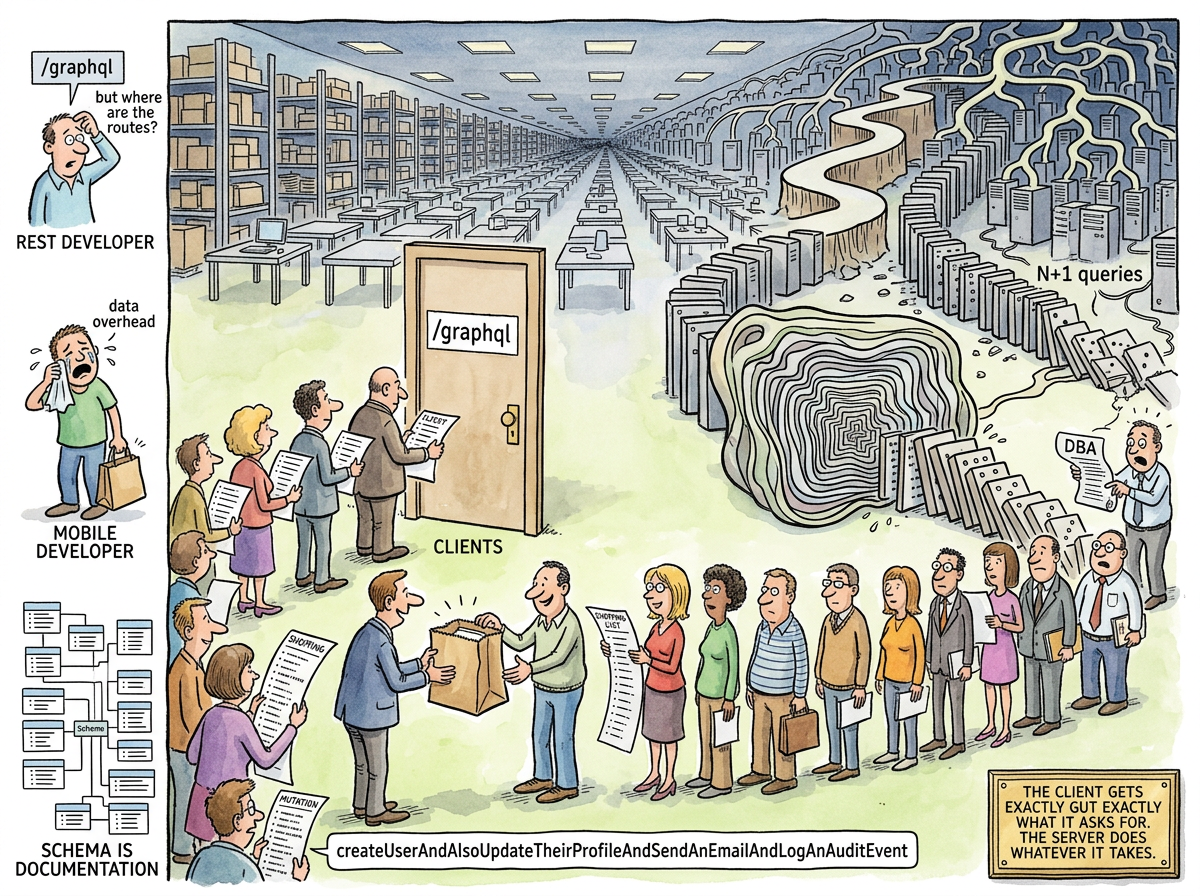
GraphQL is a query language for APIs created by Facebook in 2012 and open-sourced in 2015, which solves the problem of clients receiving too much data from REST endpoints by introducing a system where clients can request exactly the data they need — along with a new set of problems that are different from, but approximately equal in number to, the ones it replaced.
GraphQL’s core promise is elegant: instead of the server deciding what data to return (REST), the client specifies exactly what it wants. No over-fetching. No under-fetching. One endpoint. One query. Exactly the shape you need.
This is genuinely brilliant for mobile clients on slow networks who cannot afford to download fourteen unused fields. It is also genuinely terrifying for backend engineers who must now defend their database against clients who can construct arbitrarily complex queries through a single, infinitely flexible endpoint.
The Query Language
GraphQL queries describe the shape of the desired response:
query {
user(id: 42) {
name
email
posts(last: 5) {
title
comments {
author { name }
body
}
}
}
}
The response matches the query exactly. If you ask for name and email, you get name and email. Not name, email, createdAt, updatedAt, role, avatarUrl, lastLoginAt, preferences, billingAddress, and forty-seven other fields that the REST endpoint returns because someone added them in 2019 and removing them would break the mobile app.
This is the good part. This is the part that makes frontend developers weep with joy and backend developers weep with something else.
The N+1 Problem
GraphQL’s resolver architecture — where each field in the schema is resolved by a function — produces, by default, the N+1 query problem:
query {
posts { # 1 query: SELECT * FROM posts
author { # N queries: SELECT * FROM users WHERE id = ?
name # (one per post)
}
}
}
100 posts = 101 database queries. The client sees a clean, elegant response. The database sees a denial-of-service attack masquerading as a feature request.
The solution — DataLoader, batching, query planning — exists and works. But it must be implemented deliberately. REST doesn’t have this problem because REST doesn’t let the client traverse relationships arbitrarily. GraphQL’s flexibility is its power and its cost. The client gets exactly what it asks for. The server does whatever it takes.
The Security Surface
REST has many endpoints, each with its own authentication, authorization, and rate limiting. GraphQL has one endpoint. One endpoint that accepts arbitrary queries.
The security implications:
Query depth: a malicious client can nest queries arbitrarily deep — user.posts.comments.author.posts.comments.author.posts... — consuming exponential server resources. Solution: depth limiting. But what’s the right depth? Too shallow breaks legitimate queries. Too deep enables abuse.
Query complexity: even at moderate depth, a query can request expensive fields across large collections. { users { posts { comments { likes { user { name } } } } } } on a million-user database is a query that REST would never produce because REST would never expose that traversal path through a single endpoint.
Introspection: by default, GraphQL lets any client query the schema itself — every type, every field, every relationship. This is excellent for development. It is also a complete map of your data model handed to anyone who can reach the endpoint.
REST’s security model is crude but effective: each endpoint is a surface to defend, and you can see all the surfaces. GraphQL’s security model is a single surface that accepts infinite inputs. Defending it requires thinking about queries you haven’t imagined yet.
The Schema Is the Documentation
GraphQL’s genuinely great contribution — better than the query language, better than the type system, better than the single endpoint — is that the schema is the documentation.
type User {
id: ID!
name: String!
email: String!
posts(first: Int, after: String): PostConnection!
}
The schema defines the types, the fields, the relationships, the nullability, and the arguments. Tools like GraphiQL and Apollo Studio let developers explore the schema interactively, auto-complete queries, and see the types before writing a line of code.
This is what REST never had. OpenAPI/Swagger tried, but they’re bolted on after the fact — a description of the API, not the API itself. In GraphQL, the schema is the API. If the schema says the field exists, the field exists. If the schema says it’s non-null, it’s non-null.
This is genuinely, unambiguously good. The debate about GraphQL vs. REST should acknowledge this: GraphQL’s type system and self-documenting schema are contributions that the entire industry benefits from, even in REST APIs that adopted OpenAPI in response.
When to Use GraphQL
GraphQL is the right choice when:
- Multiple clients (web, mobile, TV, watch) need different shapes of the same data
- The data is a graph (users have posts, posts have comments, comments have authors)
- The frontend team is blocked waiting for backend endpoints
- You have the engineering maturity to implement DataLoader, depth limiting, complexity analysis, and query caching
GraphQL is the wrong choice when:
- You have one client
- Your data is simple (CRUD, flat resources)
- Your team is small and the operational overhead of a query language exceeds the overhead of adding a REST endpoint
- You’re choosing it because Facebook uses it and your app has 200 users
The Lizard’s API — GET /api/gallery returning JSON — is not GraphQL. It is a single REST endpoint returning a fixed shape. This is correct for a system with one client, one developer, and one shape of data. The query language that powers Yagnipedia is not GraphQL. It is SQL, which has been the query language for data since 1970 and does not require a resolver tree to ask for a user’s posts.
Measured Characteristics
Year created (internal): 2012
Year open-sourced: 2015
Endpoints per API: 1
Flexibility of that endpoint: infinite
N+1 queries (without DataLoader): guaranteed
N+1 queries (with DataLoader): mostly solved
Security surfaces (REST, 20 endpoints): 20
Security surfaces (GraphQL): 1 (accepting ∞ inputs)
Schema quality: genuinely excellent
Documentation generated from schema: automatic
Documentation generated from REST: manual (usually stale)
Frontend developer satisfaction: high
Backend developer satisfaction: it depends
DBA satisfaction: nervous
Query depth limit (recommended): 7–10
Query depth (adversarial client): ∞ (if not limited)
Apps that need GraphQL: fewer than use it
Apps that benefit from GraphQL: more than admit it