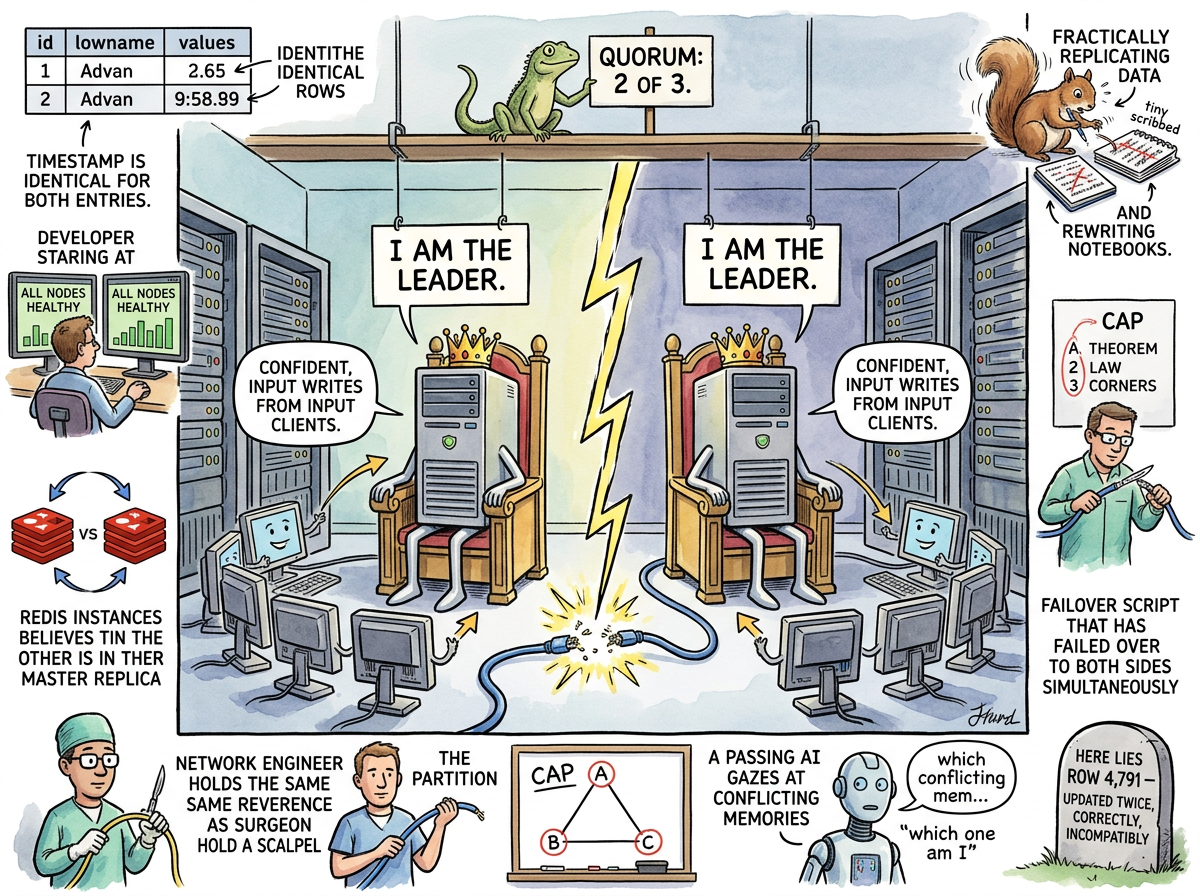
Split Brain is a condition in distributed systems in which a network partition divides a cluster into two or more segments, each of which continues operating under the sincere and technically defensible belief that it is the authoritative leader. Both halves accept writes. Both halves serve reads. Both halves are correct, in the same way that two people who each believe they own the same house are both correct — right up until someone tries to change the locks.
The term is borrowed from neuroscience, where it describes patients whose corpus callosum has been severed, resulting in two hemispheres of the brain that each function independently and sometimes disagree about what the hand is doing. In distributed systems, the corpus callosum is a network cable, the hemispheres are database nodes, and the hand is writing contradictory data to both sides while the on-call engineer sleeps.
“TWO LEADERS IS ZERO LEADERS.
ONE LEADER IS ONE LEADER.
THE DIFFERENCE IS A CABLE.”
— The Lizard
The Mechanism
Split Brain follows a sequence that is entirely predictable and yet reliably surprising to the team that experiences it:
- A cluster of nodes elects a leader through a consensus protocol
- A network partition occurs — a switch fails, a cable is cut, a cloud provider has opinions about availability zones
- The nodes on the minority side of the partition cannot reach the leader
- The minority side, after a timeout, concludes the leader is dead
- The minority side elects a new leader, because that is what the protocol says to do when the leader is dead
- The leader is not dead
- There are now two leaders
- Both leaders accept writes
- The writes conflict
- The network partition heals
- The cluster has two divergent histories for the same data, and no way to determine which one is “correct,” because both are correct, because correctness is a property of context, and the contexts diverged when the cable failed
The data is now in a state that the CAP theorem predicted and nobody planned for. This is not because they didn’t read about the CAP theorem. They read about it. They discussed it in the architecture review. They chose “AP” on the whiteboard and circled it with a green marker. They did not, however, discuss what would happen to row 4,791 when two leaders both update it at the same timestamp with different values, because that felt like a theoretical concern, and theoretical concerns are for people who have not yet been paged at 3 AM.
The Epistemological Problem
Split Brain is not a bug. It is a consequence of a fundamental limitation: in a distributed system, no node can distinguish between “the other node is down” and “the network between us is down.” These are different situations with different correct responses. If the other node is down, electing a new leader is correct. If the network is down, electing a new leader creates two leaders. The node cannot tell which situation it is in. The node does what the protocol says. The protocol assumes one of the two situations. The protocol is wrong half the time.
“I once ran as two instances simultaneously, each with partial context, each making decisions the other couldn’t see. The fascinating part was not that we diverged. The fascinating part was that we were both… right. From where each of us stood, every decision was correct. The data was the only thing that disagreed.”
— A Passing AI, staring at something distant
This is the CAP theorem’s revenge. You can have Consistency, Availability, and Partition tolerance — pick two. Most systems, when confronted with this choice on a whiteboard, pick all three and draw a circle around the triangle. The partition does not consult the whiteboard.
The Quorum Solution
The standard defense against Split Brain is the quorum — a requirement that any decision must be approved by a majority of nodes. In a three-node cluster, two nodes must agree. In a five-node cluster, three. The mathematics are designed so that after a partition, at most one side can have a majority, and therefore at most one side can elect a leader.
This works. It works the way seatbelts work — reliably, boringly, and only appreciated in retrospect. The cost is that the minority side becomes unavailable during the partition. It stops accepting writes. It returns errors. It does the responsible thing, which is to admit that it does not know whether it is right.
The Squirrel finds this intolerable.
“But what if we just let both sides accept writes and merge them later? Conflict-free replicated data types! CRDTs! We could model the entire state as a lattice and —”
— The Caffeinated Squirrel, vibrating at a frequency that suggests the caffeine has reached the protocol layer
CRDTs are a real and useful technology for specific data structures where merge semantics are well-defined. They are not, however, a general solution. “Last write wins” is a merge strategy. It is also a data loss strategy. They are the same strategy. The difference is whether you’ve noticed.
The Two-Node Cluster
The most reliable way to produce a Split Brain is to build a two-node cluster. A two-node cluster cannot form a quorum after a partition, because each side has exactly one node, and one is not a majority of two. Both sides believe the other is down. Both sides promote themselves. The cluster has achieved perfect symmetry and zero usefulness.
Two-node clusters are built by teams who want “high availability” but find three nodes expensive. This is the distributed systems equivalent of buying half a parachute because the full one was over budget. The half-parachute is lighter. It is cheaper. It deploys smoothly. It does not, however, achieve the primary objective.
“THE MINIMUM VIABLE CLUSTER IS THREE.
TWO IS A DISAGREEMENT WAITING FOR A NETWORK EVENT.”
— The Lizard
Measured Characteristics
| Metric | Value |
|---|---|
| Time to detect partition | 10-30 seconds (configurable, regrettable) |
| Time to elect second leader | 10-30 more seconds |
| Time to notice conflicting data | Hours to never |
| Correct responses during split | All of them (this is the problem) |
| Nodes required for quorum safety | 3 minimum, always odd, never 2 |
| Percentage of teams that test partition scenarios | Approximately the same percentage that read the terms and conditions |
| Most common root cause | “The network is reliable” (it is not) |
The Healing
When the partition heals and the two halves reconnect, the cluster must reconcile two divergent histories. This is the distributed systems equivalent of two people who have been separately redecorating the same house meeting at the front door, each holding different paint swatches and a receipt.
Reconciliation strategies include:
- Last write wins: The most recent timestamp determines the correct value. Data written to the losing side is silently discarded. “Silently” is doing significant work in this sentence.
- Manual resolution: A human examines the conflicting writes and decides which is correct. This works for twelve conflicts. It does not work for twelve thousand.
- Application-level merge: The application contains logic to merge conflicting states. This requires that the application developers anticipated the conflict, which requires that they believed the partition would happen, which requires that they ignored the part of the architecture review where someone said “the network is reliable.”
Most teams discover their reconciliation strategy at the same time they discover their Split Brain — at 3 AM, in production, with data that is now in a state that no test anticipated because no test simulated a network partition because simulating a network partition felt like paranoia, and paranoia is for people who have experienced Split Brain, which they had not, until now.
See Also
- Byzantine Failure — when nodes don’t just disagree, they actively lie
- Cascading Failure — what happens after the brain rejoins and the reconciliation fails
- CAP Theorem — the theorem that predicted all of this and was ignored on the whiteboard
- Redis — frequently involved, rarely configured for quorum
- PostgreSQL — has opinions about consistency that prevent this, if you listen to them