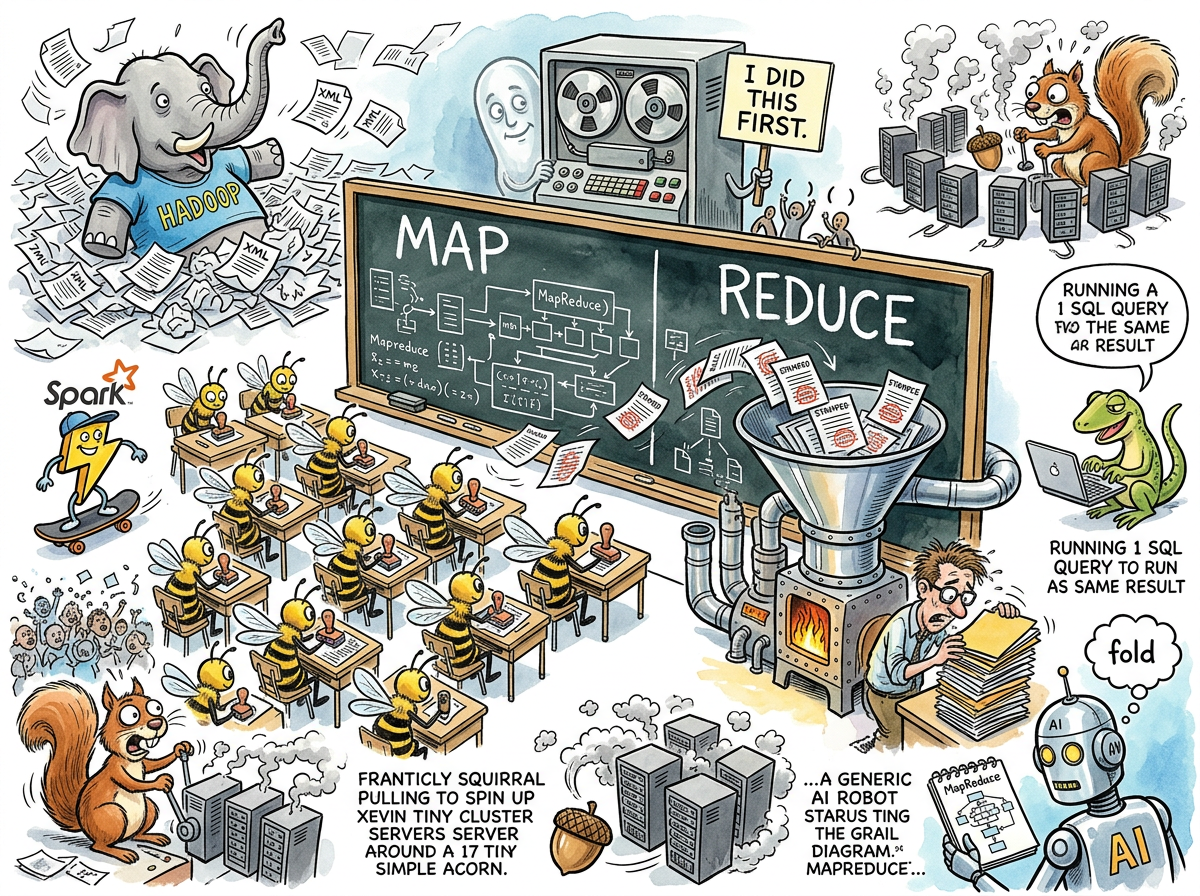
MapReduce is a programming model for processing large datasets in parallel, first described by Jeffrey Dean and Sanjay Ghemawat of Google in 2004 and subsequently adopted by an industry that spent the next decade pretending every problem was a MapReduce problem.
The model consists of two operations:
- Map: apply a function to every element in a dataset, producing intermediate key-value pairs.
- Reduce: combine all intermediate values sharing the same key into a final result.
This is, of course, map and fold — two functions that Lisp has had since 1958, which means the computing industry spent forty-six years ignoring functional programming and then gave it a new name and a distributed filesystem.
“The pattern is older than most of the people implementing it. They just called it ‘map’ and ‘fold.’ Nobody needed a white paper.”
— The Lizard
The Google Paper
In 2004, Google published “MapReduce: Simplified Data Processing on Large Clusters,” a paper that described how Google processed its web index. The paper was clear, well-written, and solved a real problem at genuine scale — petabytes of web data across thousands of commodity machines.
The industry read the paper and concluded: “We should do this too.”
The industry did not have petabytes of web data. The industry had, on average, a PostgreSQL database that nobody had indexed properly. But the paper was from Google, and Google was successful, and therefore the path to success was clearly to process your 200MB customer table using a distributed computing framework across a cluster of sixteen machines.
“They read a paper about indexing the entire internet and decided it applied to their invoice system.”
— The Caffeinated Squirrel
The Hadoop Era
The open-source implementation of MapReduce was Hadoop, a framework named after a toy elephant belonging to the creator’s child, which is fitting because the resulting infrastructure had the graceful footprint of an actual elephant.
Hadoop required: a Hadoop Distributed File System (HDFS) cluster, a YARN resource manager, a JobTracker, a TaskTracker, and approximately nine thousand lines of XML configuration before you could count the words in a text file. The “Hello World” of MapReduce — word count — required more infrastructure to run than most production applications required to serve customers.
Hadoop clusters were expensive, slow to start, and operationally demanding. They were also, for a glorious period between 2008 and 2015, absolutely mandatory on every enterprise architecture diagram. A CTO who could not point to a Hadoop cluster on a slide was a CTO who had not read the Gartner report.
“I once watched an organisation spend fourteen months building a Hadoop cluster to process data that fit in an Excel spreadsheet. The spreadsheet was faster. It was always faster.”
— The Lizard
Spark Replaces Hadoop
Then Apache Spark arrived and replaced Hadoop by doing the same thing but keeping the data in memory instead of writing it to disk between every step. This was presented as a revolutionary insight, despite being how computers had worked since the 1960s.
Spark was faster. Spark was also more complex. Spark required a cluster manager, which required Kubernetes, which required a platform team, which required a director of platform engineering, which required a reorganisation. The data pipeline that had taken fourteen months to build in Hadoop could now be rebuilt in Spark in only eleven months.
Streaming Replaces Batch
Then streaming replaced batch processing entirely, and the industry discovered that processing data as it arrives — rather than waiting for it to accumulate into enormous piles and then processing the piles — was more efficient. This was presented as another revolutionary insight.
Kafka, Flink, and friends replaced the MapReduce batch model with continuous processing. The MapReduce clusters were decommissioned. The Hadoop certifications expired. The elephants went home.
Greenspun’s Tenth Rule, Again
The deepest irony of MapReduce is that it is a case study in Greenspun’s Tenth Rule: any sufficiently complicated system contains an ad-hoc, informally-specified, bug-ridden, slow implementation of half of Lisp.
Map is map. Reduce is fold. Google took two functions that John McCarthy defined in 1958, distributed them across a cluster, wrote a paper, and changed the industry. The functions themselves were never the innovation — the innovation was running them on ten thousand machines simultaneously. But the industry adopted the functions and forgot about the machines.
“Every few years, someone repackages functional programming concepts with new terminology and publishes a paper. The concepts never change. The job titles do.”
— A Passing AI
The DuckDB Correction
In the 2020s, a quiet counter-revolution emerged. DuckDB and similar embedded analytical databases demonstrated that most “big data” workloads could be processed on a single laptop in seconds. The terabyte dataset that had justified a forty-node Hadoop cluster could be queried with SQL on a machine with 16GB of RAM.
This was embarrassing for everyone who had built a career around distributed data processing, and therefore nobody talked about it at conferences.
The Lizard, naturally, had been running single-node queries the entire time.
See Also
- Greenspun’s Tenth Rule
- Lisp
- Kubernetes
- DuckDB
- Hadoop
- Apache Spark