A branch is a parallel line of development in a version control system, created when a developer wishes to make changes without affecting the main codebase, which is to say, when a developer wishes to postpone the problem of reconciling their work with reality.
The branch is, at its most fundamental, a confession. It says: I am about to do something, and I am not confident it will work, and I would like the option of pretending it never happened. This is an entirely reasonable position for a human being to occupy, and it is remarkable that it took until 1982 for someone to formalize it into software.
History
The Before Times
Before version control, developers coordinated file changes through a sophisticated protocol known as “yelling.” A developer who wished to modify parser.c would announce this intention to the room. If another developer was already modifying parser.c, a brief negotiation would occur, typically resolved by whoever had seniority, louder vocal cords, or proximity to the coffee machine.
This system worked surprisingly well for teams of one to three people and catastrophically for everyone else.
RCS and the Lock
Walter Tichy’s Revision Control System (1982) introduced the concept of file locking — a mechanism by which a developer could claim exclusive ownership of a file, edit it, and then release it back to the commons. This was not branching per se, but it established the foundational insight that would later give rise to branches: humans cannot be trusted to edit the same file simultaneously.
CVS and the Optimistic Illusion
CVS (1990) introduced concurrent editing with merge-on-commit, an approach best described as “optimistic concurrency control,” or less charitably, as “we’ll cross that bridge when we come to it, and by ‘bridge’ we mean ’three-way merge conflict in a binary file.’”
It also introduced branches proper, though CVS branches were sufficiently painful to create and merge that most teams treated them the way one treats a fire extinguisher — theoretically available, practically used only in emergencies, and ideally never.
Git and the Cambrian Explosion
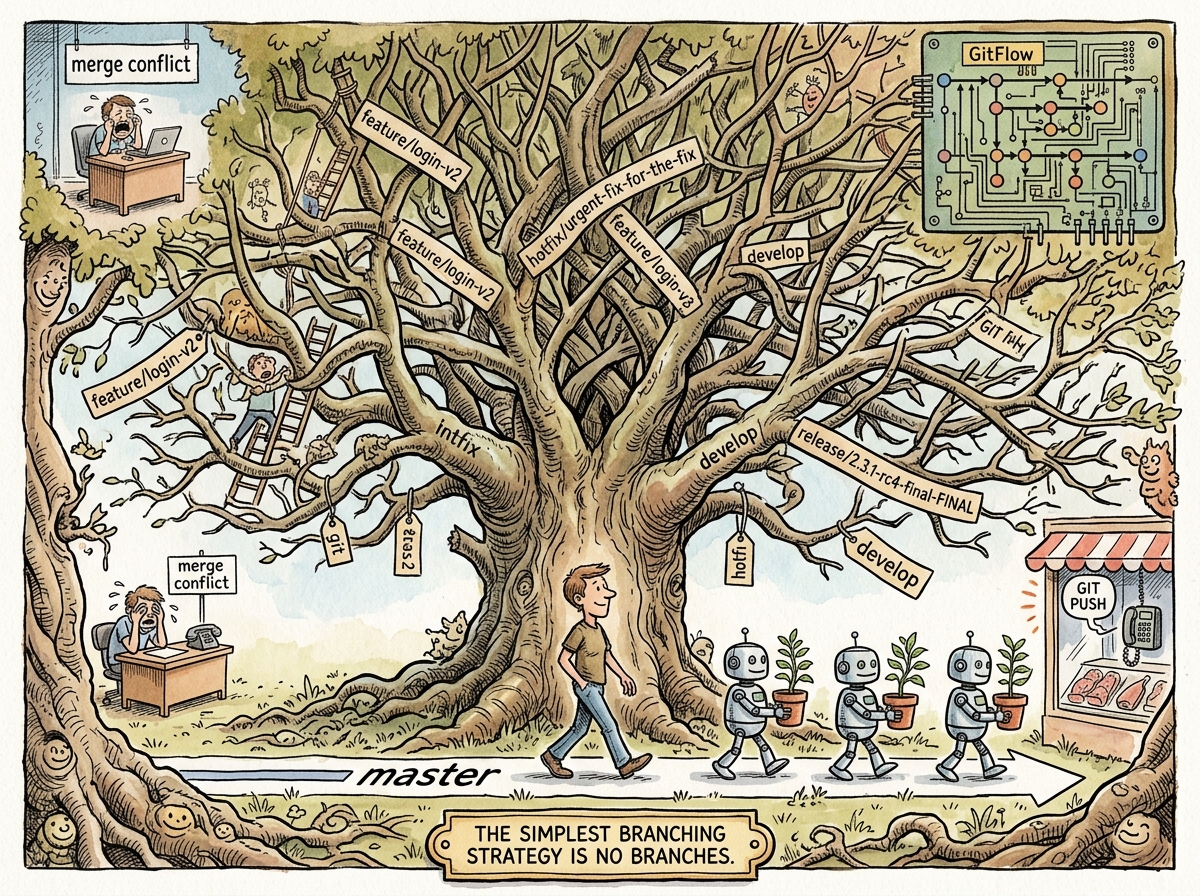
In 2005, Linus Torvalds created Git, in which branches are so cheap to create that they cost essentially nothing. This was, in retrospect, like making ammunition free. The number of branches in the average repository underwent what evolutionary biologists would recognize as an adaptive radiation event, filling every conceivable ecological niche: feature branches, release branches, hotfix branches, personal branches, experimental branches, and the dreaded old-master-backup-DO-NOT-DELETE-ask-james.
> BRANCHES ARE CHEAP, THEY SAID.
> WHAT THEY DIDN'T MENTION IS THAT CHEAP THINGS
> ACCUMULATE UNTIL THEY ARE EXPENSIVE.
> — THE LIZARD 🦎
Why Branches Exist
Branches exist because humans disagree about code. Not in the philosophical sense — though that too — but in the mechanical sense that two humans cannot type different characters into the same line of the same file at the same time without producing nonsense.
The branch is the version control system’s answer to this limitation. Rather than forcing agreement in real time, it allows disagreement to proceed in parallel, deferring reconciliation to a future moment known as “the merge,” which is spoken of in the same tone that medieval peasants reserved for “the harvest” — something inevitable, seasonal, and occasionally devastating.
There are secondary justifications, of course. Code review. CI/CD gates. The psychological comfort of knowing that one’s half-finished work is not visible to the production server. These are valid. But the root cause remains coordination failure, dressed up in workflow diagrams.
The Branching Strategy Industrial Complex
Once branches became cheap, an entire consulting ecosystem emerged to answer a question that no one had previously thought to ask: how should we organize our branches?
GitFlow (2010)
Vincent Driessen’s GitFlow model introduced five categories of branches (master, develop, feature/*, release/*, hotfix/*) and a diagram so elaborate that it has been compared to a London Underground map, a circuit board, and — by one particularly candid commenter — “the family tree of European royalty, with similar levels of inbreeding.”
GitFlow is the correct branching strategy for a team of forty developers shipping quarterly to an environment where deployment requires a change advisory board, a signed form, and three weeks of regression testing. It is also the branching strategy most frequently adopted by teams of four developers deploying to Heroku on every push, because the blog post was very convincing.
GitHub Flow
GitHub Flow simplified matters to a single rule: branch from main, open a pull request, merge when ready. This was received with the relief of a traveller who, after studying a 200-page transit map, discovers they can simply walk.
Trunk-Based Development
Trunk-based development advocates for the radical position that everyone should commit to the main branch, using feature flags to hide incomplete work. Its proponents speak of it with the quiet confidence of someone who has discovered a fundamental truth. Its detractors point out that feature flags are just branches that live in your configuration system instead of your version control, which is like solving a mess in your garage by moving everything to the attic.
The Squirrel’s Contribution
The Caffeinated Squirrel, upon reviewing the landscape of branching strategies, proposed CamelBranchFlow — a system in which every branch name must be written in CamelCase and must describe the developer’s emotional state at the time of creation (AnxiousRefactorOfPaymentModule, OptimisticNewCachingLayer, DesperateHotfixAtMidnight). The proposal was not adopted, though it would have provided more useful information than most branch names currently do.
The Retirement of Branches
In certain vocabularies — specifically, the vocabulary of one riclib — the word “branch” has been retired from active duty. Not deprecated, not discouraged, but retired, in the way that a jersey number is retired: with full honors and no intention of ever using it again.
The mechanism is simple and, in the way of all genuinely good ideas, sounds slightly unhinged when first described:
Four AI agents. Four OrbStack virtual machines. One repository. One branch: master. No feature branches. No pull requests. No merge ceremonies. Just git push and git pull, all day, every day, like a well-oiled factory where the workers happen to be large language models with their own computers.
> [riclib](/wiki/riclib): "No branches. Four agents. One master. Ship it."
The Thursday Nobody Needed a Branch
The full account of how this arrangement came to be is documented in The Factory Floor, or The Thursday Nobody Needed A Branch, but the essential facts are these: on an ordinary Thursday, four Claude agents were working on different parts of the same codebase. Agent One was refactoring the credential store. Agent Two was adding a new provider type. Agent Three was writing tests. Agent Four was updating the UI. All of them were pushing to master. None of them created a branch.
And nothing broke.
Or rather — things broke in the way that things always break in software development, but they were fixed in the same push cycle, by the same agents, without any human needing to open a terminal, read a diff, or experience the particular despair that accompanies a merge conflict in a .templ file.
The Key Insight
Branches exist because humans cannot resolve conflicts in real time. A human developer, confronted with a git push rejection, must perform the following ritual:
git pull- Read the diff
- Understand what the other developer intended
- Understand what they themselves intended
- Determine whether these intentions are compatible
- If not, negotiate (via Slack, email, or an increasingly tense stand-up meeting)
- Resolve the conflict
- Test
- Push
- Discover a new conflict has appeared in the interim
- Return to step 1
This process, which can take anywhere from two minutes to two sprints, is the reason branches exist. The branch is a buffer against the latency of human comprehension.
Claude is not subject to this latency.
When an agent’s git push fails, it performs the same ritual, but with a critical difference: steps 2 through 6 take approximately four seconds and do not involve feelings. The agent pulls, reads the diff, understands both intents — the remote change and its own — adjusts its work accordingly, and pushes again. It is, in effect, git merge with a 190 IQ.
> A MERGE CONFLICT IS JUST A CONVERSATION
> BETWEEN TWO SETS OF INTENTIONS.
> MOST MERGE TOOLS SHOW YOU THE WORDS.
> CLAUDE READS THE MEANING.
> — THE LIZARD 🦎
The Evolution of AI-Assisted Merging
The current arrangement did not appear fully formed. It evolved through three distinct phases:
Phase 1: The Human Merges (with AI help)
riclib would encounter a merge conflict, copy the conflicting hunks into ChatGPT, explain the intent of both sides, and ask for a resolution. ChatGPT would suggest a merged version. riclib would paste it back into the file, test, and commit. This was faster than manual merging but still required a human in the loop — specifically, a human with a clipboard and enough patience to context-switch between a terminal and a browser tab.
Phase 2: The Human Orchestrates (AI resolves)
The process improved: the AI could see more context, understand the broader codebase, and suggest resolutions with higher confidence. But someone still had to notice the conflict, invoke the AI, and apply the result. The human had been promoted from “merge tool operator” to “merge tool supervisor,” which is the kind of promotion that doesn’t come with a raise.
Phase 3: The AI Is the Merge
In the current arrangement, there is no merge step because there is no human in the loop. The agent encounters the conflict, resolves it, and moves on. The human learns about the conflict in the same way they learn about the weather in a city they don’t live in: as an interesting fact in a log file, noticed hours or days later, if at all.
> riclib: "I used to resolve merge conflicts. Now I read about them in the commit log. Sometimes."
Why Not Git Worktrees?
The observant reader may wonder why Git Worktrees — Git’s built-in mechanism for maintaining multiple working directories from a single repository — were not the solution. They were, in fact, tried. The experiment is documented in Git Worktrees and the conclusion can be summarized as: worktrees work, but they share a single .git directory, which means they share lock files, which means concurrent operations occasionally produce errors that are technically recoverable but spiritually draining.
The solution was simpler and, in the grand tradition of systems engineering, more expensive: give each agent its own computer. An OrbStack VM is lighter than a Docker container and heavier than a thought, which places it in the ideal weight class for “thing you can spin up four of without thinking about it.” Each VM gets its own full clone of the repository. No shared state. No lock contention. No worktree weirdness. Just four independent copies of reality, reconciled through the oldest distributed systems protocol available: push and pull.
> riclib: "Worktrees share a brain. VMs don't. Solved."
Philosophical Implications
The retirement of branches from a solo developer’s workflow raises an uncomfortable question for the broader industry: how much of our branching infrastructure exists to solve a technical problem, and how much exists to solve a social one?
Feature branches, pull requests, code review gates, merge queues — these are, in significant part, mechanisms for managing trust. We branch because we do not trust that the code being written by the person across the office (or across the ocean) is compatible with our own. We require pull request approval because we do not trust that the code is correct without a second pair of eyes. We maintain staging branches because we do not trust that the code is ready for production.
When the “person across the office” is an AI agent that you configured, that runs your test suite before pushing, and that can read and understand every file in the repository, the trust calculation changes. Not because the agent is infallible — it is not — but because the feedback loop is measured in seconds rather than hours, and the cost of a mistake is a revert rather than a meeting.
This is not to suggest that branches are unnecessary for all teams. A team of fifty humans absolutely needs branches, for the same reason that a city of fifty thousand people absolutely needs traffic lights. But a single developer with four AI agents is not a city. It is closer to a person with four hands, all of which are attached to the same nervous system.
The simplest branching strategy is no branches.
See Also
- Git — The version control system that made branches free and thereby ensured their overuse
- Git Worktrees — The middle path, attempted and found wanting
- The Factory Floor, or The Thursday Nobody Needed A Branch — The historical account
- Merge Conflict — The disease for which branches are the treatment and AI is the cure
- Solo Developer — The context in which branchless development is not insanity
- OrbStack — The hypervisor that made “give each agent its own computer” a casual decision
- Claude Code — The agent that made “git merge with a 190 IQ” a description rather than a metaphor